| News Details |
Evidence Identification in Heterogeneous Data Using Clustering
2022-04-23
|
Hussam Mohammed1 Centre for Security, Communications and Network Research University of Plymouth hussam.mohammed@plymouth.ac |
Nathan Clarke2 Centre for Security, Communications and Network Research University of Plymouth N.Clarke@plymouth.ac.uk |
Fudong Li3 Centre for Security, Communications and Network Research University of Plymouth fudong.li@port.ac.uk |
ABSTRACT
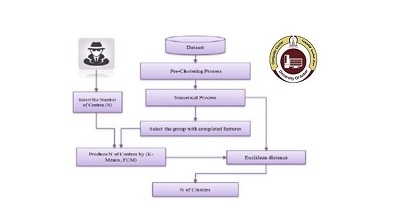
Digital forensics faces several challenges in examining and analyzing data due to an increasing range of technologies at people's disposal. The investigators find themselves having to process and analyze many systems manually (e.g. PC, laptop, Smartphone) in a single case. Unfortunately, current tools such as FTK and Encase have a limited ability to achieve the automation in finding evidence. As a result, a heavy burden is placed on the investigator to both find and analyze evidential artifacts in a heterogenous environment. This paper proposed a clustering approach based on Fuzzy C-Means (FCM) and K-means algorithms to identify the evidential files and isolate the non-related files based on their metadata. A series of experiments using heterogenous real-life forensic cases are conducted to evaluate the approach. Within each case, various types of metadata categories were created based on file systems and applications. The results showed that the clustering based on file systems gave the best results of grouping the evidential artifacts within only five clusters. The proportion across the five clusters was 100% using small configurations of both FCM and K-means with less than 16% of the non-evidential artifacts across all cases -- representing a reduction in having to analyze 84% of the benign files. In terms of the applications, the proportion of evidence was more than 97%, but the proportion of benign files was also relatively high based upon small configurations. However, with a large configuration, the proportion of benign files became very low less than 10%. Successfully prioritizing large proportions of evidence and reducing the volume of benign files to be analyzed, reduces the time taken and cognitive load upon the investigator.
Link.....