| News Details |
?Version/Source control (VSC)
2022-04-28
Nowadays, software is involved or embedded in every aspect of our life. Almost everything is running based on some type of software from space rockets to simple calculators. Every software goes through cycles and series of development and changes to reach a final and accepted case. Managing these changes is a challenging task for the software development team and managers. So, finding a way that can ease this change become a priority for researchers and developers. In the 1970s, the first system that can provide the needed functionality was developed by IBM. From that day, the journey of the source control system started.
In short term, it is tracking and managing changes to code.
In long term, it is a system that is responsible for managing and tracking any changes that occur on targeted code without the need to store duplicated documents or code. We say document because source control can track changes on any type of text document.
Why do we need Source control?
Whether you are building a simple application or a large system, modifications are inevitable. Source control is not just for managing changes but also useful for collaborative software development due to the ability to merge different changes made to the main document. The most company consider it a vital component in their software development life cycle, that because it provides following benefits:
1- History revision of the code/document. The system stores versions of code on every change made. The version is not a complete copy of the code, but it is just what change since the last version. Every time developer commits changes, VSC creates a new version of the corresponding document.
2- Ability to revert to the previous version. If something happened that breaks the code, the developer easily can revert to any previous version of the code without losing any information. This issue may not happen a lot, but it will be a life saver when a problem arises. At the same time, developers can use it to compare between versions to see the differences and troubleshoot the issue.
3- Track code changes, what changes, and who made the changes. Most source control tools provide the ability to see what has been removed or added and who made the changes. This allows the team leads to review changes to approve or send back for improvement.
4- Collaboration on code: multiple team members can work on the same project at an isolation level until the code is ready to publish. So, any member who made changes to the project will not impact what other members do until they merge into the main version of the code.
5- Automate the process with DevOps. Using control sources consider the best practice for automated software development life cycle with DevOps. Having a reliable repository make another testing, packaging, and development tool have a reliable source (repository) that depends on to get the latest version of the code, with minimum human interaction.
Structure of Source Control
The basic principle of VSC is storing files with all their information and versions associated with them in the repository. The repository includes the latest versions of each document and all history of modifications unit the current stage, in addition to information related to these versions such as date and time, author, and description. During the history of the development of the VSC system, VSC was used in four different repository models:
1- Local: at an early stage of use VSC repository was kept locally and only the owner the person who can access the machine can interact with it. This limits the team to collaborate on a single project.
2- Shared folder: to overcome the limitations, the team stored a repository in a shared folder where the team on the same local network can access it.
3- In a large company using a shared folder is challenging. Client/server used to address this challenge. In which, repositories are stored on a server and every client can access (with permission)
4- Distributed repository: in which every user/developer has his/her local repository that they constantly updated and mostly keep synchronized with a remote online repository which shared with others.
From the above, you can conclude that there are two types of VSC systems; centralized and distributed. In recent years, the distributed VSC has gained more attention because it allows collaboration without the need for a central repository.
Centralized Version Control
A centralized type was developed to overcome the challenge that developers faced when multiple developers work on the same systems. In this type, there is a single machine that stores the main copy of file versions history and keeps track of all changes and their information. It is called centralized because there is a central server or computer that holds the repository and all the version and maintain a complete record of all change and issues, whereas the developers can check out locally the project from the central server. To make changes developers can check out the needed project from the server and make their modifications which will be shared automatically with all developers. Developers in centralized type can only check out the latest version of a project from the repository to make their modifications on. This type has some drawbacks:
1- Inaccessible sever would prevent developers from pushing the latest change to the server.
2- Everything will be lost if the centralized repository got corrupted.
3- Because there is a single copy, there should be a restriction on making the change on it. This restriction will reduce the number of participations.
Distributed Version Control
Distributed type was developed to overcome the drawbacks of centralized by providing the ability to branch and merge, reducing the restriction of the local repository. This type works on keeping the entire history records of change on each local computer and syncing them with a remote server if needed. Because of that, developers can collaborate on a project and made their modifications (with all versions) without impacting others. At some point, they will push their change to the remote server to be accessible by other developers. There is three main advantage of using distributed type:
- Flexibility comes from easy to work independently but in a collaborative environment,
- Online hosting services, like GitHub, which remote access to teams across the world,
- Availability, the repository will always be available online even if the local was corrupted,
- it doesn’t require access to remote servers to make the change,
- branching and merging can be done very easily.
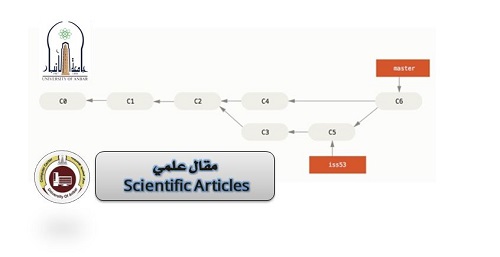
Concept of Branching and Merging
Suppose you are working on software for a company that automates their work. One day, one of the divisions asked you to make some tweaks to one of the processes to match this division's needs. In this case, you as a developer can’t modify the main repository; however, you need to create a secondary one. Version control provides branching to help address this situation. The developer can create another branch from the main one and modify it as needed without impacting the main branch. This concept can be used to create different applications from the main application, add/test new features, and restrict direct change on the main branching. After finishing development, the new branch can be kept as new software or it can be merged into the main branch.
Git is a distributed version control, and it is one of the most popular version controls used nowadays. It was developed in 2005 as a free open source which made it a desirable tool for many companies to implement an extended version based on it for their profit. Every time developer makes a change and committed, Git either stores a reference to the old file if not has changed or takes a new snapshot of the file that changed. This versioning by Git is done locally on the developers' computer (compatible with Linux, Windows, macOS), but it can be linked to a remote repository (GitHub, BitBucket,…). To keep track of changes made on files, Git used SHA-1 to checksum the content of files/directories. This helps Git in detecting if there is any change made to files without the need to compare them comprehensively.
Losing data is not easy when using Git. After committing the change, Git stores the new version of file(s) without modifying the old one and stores the information in a database. For that reason, the most senior developer recommends committing frequent after finishing a functional code. To check your local repository state, git provides three states that describe the current situation:
- Modified: This means the current content of a file does not match the one in the repository due to some changes which have been made.
- Staged: file that has been modified and checked to be ready for commit. It kind of lists of files to which they will be committed. If a file is modified but not staged, then it will not be committed.
- Committed: It means the change has been added to the repository and the information was stored in the database.
Starting with Git
Git has many commands line that is very useful in different situations. This article will list the most common one that developer needs to know to start using Git.
1- git init
Running this command inside the project directory will create a subdirectory called “.git” which will contain all the necessary files, but at this point, nothing will be tracked by Git. If the project already has files that need to be tracked, then used add command
2- git add .
This command will be added everything in the current path to versioning control. If you need to add a specific file, then you can replace the dot “.” with the file name or you can use an expression to match all files of the same type.
3- git commit -m “message”
This command will go through all the files that have been added and store them safely. The -m is require adding a description of what this commit is about or what has been changed.
4- Git status
Used to display the state of the directory and lets you know which changes have been staged (added) and which haven't.
5- Git clone repository_path
Is used to create a new full copy of an existed repository.
6- Git push
After committing, change ware store on the local machine but the remote repository branch has not been updated with the new change. This command will push the change to the remote repository with all information.
7- Git pull
If someone else made a change on the remote repository that you have a clone, these changes will not be on your local machine. To get the recent version of a remote repository, this command is used.
8- Git checkout
This command has many ways to be used, but basically, it asks git to get a specific version of the project from the repository. Specifying the version can be based on the branch name or commit id.